
from IPython.core.display import HTML, Markdown, display
import numpy as np
import numpy.random as npr
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
import statsmodels.formula.api as smf
import pingouin as pg
import math
import ipywidgets as widgets
import ipywidgets as widgets
from IPython.display import display, Markdown, clear_output
import numpy as np
import pandas as pd
import os
from datetime import datetime
from ipycanvas import Canvas, hold_canvas
from sdt_exp import *
# Enable plots inside the Jupyter Notebook
%matplotlib inline
Signal detection: Part 2¶
Authored by Todd Gureckis
In the previous lab you learned some of the basic analysis steps involved in signal detection analysis. In particular, we learned how to compute a statistic we called d’ (dprime) and c (bias/criterion). These variables are commonly used in studies of perception to understand the performance of a subject on a task independent of their response bias (here meaning tendency to give a particular response).
In the second part of the lab we will analyze data from a simple detection experiment you will have just conducted on yourselves. You will get to put your python knowledge into practice by reading in the data analyzing it.
The Experiment Instructions¶
In this experiment you job will be similar to that of a doctor. There are going to be small “clusters” of points which we might think of as a tumor or some other biological measurement. You can use the interaction element below to examine a few of these “clusters”.
Try using the widget below to slide between a lot of dots within a cluster and a small number. Sweep back and forth and get an idea of what a “cluster” could look like. The dots are spread out to a certain degree as you can see more clearly with the large number of dots.
@widgets.interact(dots=(1,75, 5))
def draw(dots):
return draw_stimulus(include_source=True, n_background_dots=0, n_source_dots=dots, source_sd=10, source_border=20, width=400, height=400)
The challenge is that these dots are going to be hidden in a background of “noise” which is other dots unrelated to the cluster. Here is an example of the background with no cluster present:
draw_stimulus(include_source=False, n_background_dots=30*30, n_source_dots=0, source_sd=10, source_border=20, width=400, height=400)
You can run the above cell many times to see different example patterns when the cluster is absent.
Next here is an example of a very large cluster hidden in the background noise:
draw_stimulus(include_source=True, n_background_dots=30*30, n_source_dots=60, source_sd=10, source_border=20, width=400, height=400)
From this example you can see a very clear “cluster” or tumor in the stimulus. Here is one where there is a cluster/tumor but it is a little less obvious:
draw_stimulus(include_source=True, n_background_dots=30*30, n_source_dots=50, source_sd=10, source_border=20, width=400, height=400)
Finally, here is one where it is pretty hard to tell that there is a cluster at all (oh but there is one involving only 20 dots!):
draw_stimulus(include_source=True, n_background_dots=30*30, n_source_dots=20, source_sd=10, source_border=20, width=400, height=400)
Your job in the experiment will be to view stimuli such as the ones above and judge if you think there is a cluster/tumor present in the image. It can often be hard to tell because even in the random dots there can be little clusters of dots that group together. Just try to do your best. Notice that there is a red “absent” button and a green “present” button. You should press “absent” if you think the cluster/tumor is not there, and press “present” if you think it is there. There are 100 trials overall.
Before running the next cell set the subject number to your NYU netid (I will anonymize this later but will let me check that everyone has done the experiment).
Run the Experiment!¶
subject_number = 'bl1611' # set your subject number here
exp = Detection_Experiment(subject_number)
exp.start_experiment()
Getting the data¶
After you run the experiment, the data will be output to a .csv file tied to your subject number. Also it is available as as pandas data frame in the current kernel environment as exp.trials:
exp.trials.head()
| signal_present | signal_type | trial_num | button_position | subject_number | |
|---|---|---|---|---|---|
| 0 | 1 | 60 | 0 | left | bl1611 |
| 1 | 1 | 10 | 1 | left | bl1611 |
| 2 | 1 | 10 | 2 | left | bl1611 |
| 3 | 1 | 15 | 3 | left | bl1611 |
| 4 | 0 | 0 | 4 | left | bl1611 |
Experiment design¶
In the experiment, you saw a number of trials where field of random colored and positioned dots appear. On some trials a small “cluster” of points was added to the stimulus. The number of dots in the cluster was manipulated across conditions so that it was more or less obvious that there was a cluster. In some cases the number of dots within the cluster was so small that it was hard to detect it, but other cases it might have been more visually obvious. This is very similar to the type of visual diagnosis that a doctor or airport screener might perform (deciding of a tumor or a gun is present in an image). Your task was to indicate if it was a “stimulus/cluster present” trial or a “stimulus/cluster absent” trial. The computer recorded your response and your reaction time.
An overview of the situation is shown here:
The things we manipulated!¶
There were actually four different types of clusters shown on any given “stimulus present” trial. One was a small stimulus made up of 10 dots, one was a medium made up of 15 dots, one type of made up of 25, and finally one was made up of 60 dots:

As the number of dots increases the general visibility of the cluster becomes more clear and easier to detect.
In total there were 100 stimulus absent trials and 25 of each of the four types of stimulus present trials. The purpose of this was so that a perfect subject with robot-quality vision would say “yes” half the time in the experiment so there is no overall bias toward one response.
In this lab we are interested in analyzing the effect of strength of the stimulus cluster (i.e., number of dots) on the two signal detection variables we learned about in the previous lecture and lab.
Analysis Steps¶
Remember from the previous lab that our model for signal detection looks something like this:
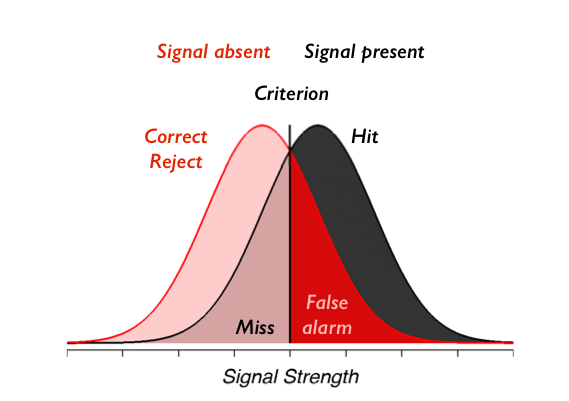
and we showed how we can compute \(d'\) and \(c\) by computing only the number of false alarms and hits and subjecting those to a particular mathematical transformation. In this case we actually have four stimulus conditions (10, 15, 25, or 60). So our goal will be to compute the hits and false alarms separately for the two different types of stimuli. This will mean that each person in our experiment will be described by eight numbers:
A d’ (d-prime) under (10, 15, 25, 60) visibility cluster conditions
A c under (10, 15, 25, 60) visibility cluster conditions
Once we have this we want to perform a simple hypothesis test. Is performance, measured by d’ higher in the high visibility conditions? We have strong reason to suspect this is the case but it’ll be a nice check of our understanding if we can related the abstract calculation we performed in the previous lab to answer this simple quesiton.
Answering this question will push our skills at using pandas to organize our data, and using pingouin to compute a t-test.
When computing d-prime with real data, sometimes we run into issues if the hit rate is perfect (1.0) or the false alarm rate is perfect (0.0). D-prime is undefined in these cases, and it’s likely unrealistic anyway to assume that the rates are really perfect. Thus, to keep the calculations numerically stable, please use ppf_smooth (see below) as a replacement for stats.norm.ppf. This new function uses uses 0.01 as the minimum rate, and
0.99 as the maximum. (There are somewhat more elegant ways to do this if you are publishing your analyses, see this link, but this will be okay for our purposes here).
def ppf_smooth(rate):
# Replacement for stats.norm.ppf that uses 0.01 as the minimum rate, and
# 0.99 as the maximum
#
# Input:
# rate : either hit or false alarm rate
assert(rate >= 0. and rate <=1.) # rate must be between 0. and 1.
rate = max(rate,0.01)
rate = min(rate,0.99)
return stats.norm.ppf(rate)
If we compute one $d'$ for each participant for each stimulus conditon and want to compare performance in two different stimulus conditions, what type of t-test should we most likely use?
Enter your plan for the analysis as a markdown cell.
To begin we want to read in the data from each participant into a pandas data frame using `pd.read_csv()` and the used `pd.concat()` to combine them. After you read in the data, inspect the columns and check the data for any inconsistencies that might affect our analysis (e.g., subjects who didn't perform any trials, etc...).
Enter your code here.
As a reminder the following show a simple for loop (called a list comprehension) that lets you get the filenames for the lab data set. You can use this to find the file names that you need to read in with pd.read_csv(). If you need a reminder refer back to your mental rotation lab which should be on your Jupyterhub node still!
# this is an example list comprehension which reads in the all the files.
# the f.startswith() part just gets rid of any junk files in that folder
filenames=['sdt1-data/'+f for f in os.listdir('sdt1-data') if not f.startswith('.')]
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-11-867726fa727e> in <module>
1 # this is an example list comprehension which reads in the all the files.
2 # the f.startswith() part just gets rid of any junk files in that folder
----> 3 filenames=['sdt1-data/'+f for f in os.listdir('sdt1-data') if not f.startswith('.')]
FileNotFoundError: [Errno 2] No such file or directory: 'sdt1-data'
Did you find any interesting or important points about the data that you want to share with the class? Let's get everyone on the same page so we get similar results so if you find something important (good or bad) please take a moment and share!
Now that we have the analysis dataframe, let's perform our planned SDT analysis on a single subject. In the cell below, create a new dataframe by subselecting from the main frame with the data from a single subject.
Enter your code here.
Referring back to the first notebook from the lab, compute the hits and false alarms for this subject for each stimulus present condition. One note about the false alarms: remember that false alarms are trials where the stimulus was absent but the subject said it was present. There is only one type of these false larms trials in the experiment. So when you compute the statistics, you really will create five numbers for this one participant (The hits for each of the stimulus present conditions, and an overall false alarm rate). What are these numbers for this subject? Remember also that if you take the `mean()` of a column of 0/1 values it will tell you the proportion of those trials which are 1.
Enter your code here.
Ok now compute the d' and c values for this subject. Refer back to the previous notebook for reference if you need the equations and python code. What can you tell from looking at your computed values? If for some reason you can't compute these values in your experiment (e.g., if the subject has no hits or no false alarms) then try question 4 again with a different subject.
Enter your code here.
Ok, so now you have performed the desired analysis for one subject. You have computed eight numbers for that subject described above. Now we want to repeat this for each subject. There are two ways to do this. One is using the pandas groupby() function. This is somewhat of the advanced mode version but if you do this you can probably perform the analysis in only 5-6 lines of code. An alternative approach is to generalize the code you just wrote to use a for loop that iterates over each subject in the data frame. Which ever way you choose you might find it helpful to refer to the Forty For Loops notebook I provided which shows some example templates for using for loops to analyze individual subject data in pandas dataframes. The end result is that you want a dataframe containing the d' and c' for each subject for each stimulus condition.
Enter your code here.
Now that you have your summary statistics computed, our next step is to ask if the conditions are different on either the d' or c measure. For now concentrate on the easiest and hardest conditions to see if there is a effect in the most dissimilar conditions. Then compare the hardest and second hardest conditions. Conduct the appropriate t-test to tell if these conditions are different. The chapter reading from this week has all the code you need. However you might find it helpful to refer to the pingouin documentation for the t-test function.
Enter your code here.
This question is a bonus but asks you to verify the assumptions of the chosen t-test hold. Usually this involves looking to see that the distribution of scores you are analyzing are roughly "normally" distributed. The textbook showed a few example way to check including the histogram, the qqplot, and the Shapiro-Wilks test. Perform this test on your data. If the data seem very non-normal you might consider switching your t-test to the non-parametric alternative discussed in the chapter (the wilcoxon or Mahn-Whitney test).
Enter your code here.
Ok great job! You have your data, you have your t-test, you have everything you need to answer the following questions: 1. Is performance higher in the low number of dots or high number of dots condition? How do you know? How would you report the statistical evidence in favor of your conclusion in a paper? Is the criterion different between the conditions? How do you know? Overall was performance high or low in this task?
Enter your Markdown text here.
The final question asks you to consider limitations to this experiment design. What other analyses might be interesting to perform on this data? If you could change the experiment is there another type of question you would ask?
Enter your Markdown text here.