Research Blog
Discussions and insights about our recent papers on AI foundations, machine learning theory, and reasoning in large models.
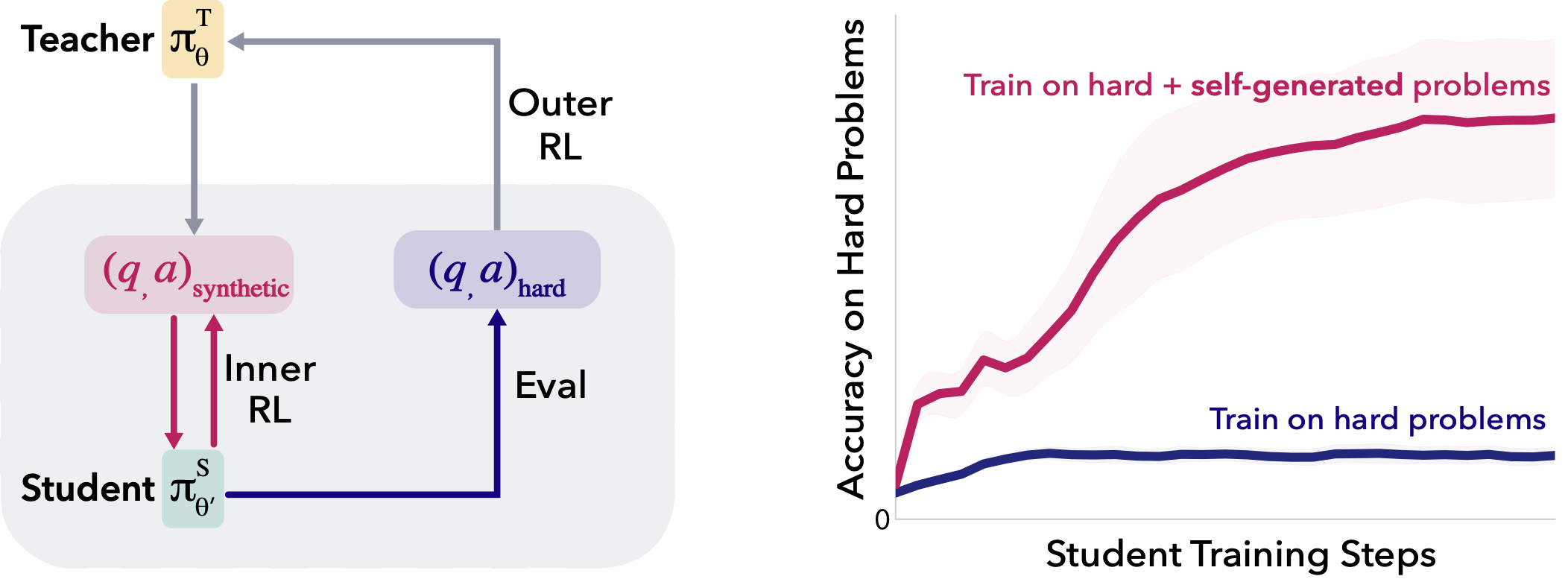
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
January 25, 2026 | Written by Shobhita Sundaram
Authors: Shobhita Sundaram (MIT), John Quan (Meta FAIR), Ariel Kwiatkowski (Meta FAIR),
Kartik Ahuja (Meta FAIR), Yann Ollivier (Meta FAIR), Julia Kempe (Meta FAIR, NYU)
TL;DR
We show that LLMs stuck on sparse-reward, difficult math problems can self-improve by learning to
generate a "stepping-stone" curriculum with meta-RL. This allows models to improve over reasoning
plateaus without curated intermediate data or unstable intrinsic rewards.
Soft Tokens, Hard Truths
A New Approach to Training Chain-of-Thought in Large Language Models
December 12, 2025 | NYU Center for Data Science
Authors: Natasha Butt, Ariel Kwiatkowski, Ismail Labiad, Julia Kempe, Yann Ollivier
When large language models try to show their work, things can go wrong. These models often improve
at solving math or logic problems when they generate intermediate steps — a method known as
Chain-of-Thought (CoT) prompting — but learning how to do that can make them rigid.
Rather than forcing the model to commit to one path of reasoning during training, this work lets
it explore many possibilities at once using "soft" tokens — blurry combinations of multiple words
or ideas instead of a single, fixed one. During inference, however, the CoT is generated in normal
hard text. That combination — training soft, inferring hard — turned out to be the most effective.
What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of Chain-of-Thought
When More Thinking Makes Things Worse: Study Reveals the Hidden Pitfalls of Long AI Reasoning
December 5, 2025 | NYU Center for Data Science
Authors: Yunzhen Feng, Julia Kempe, Cheng Zhang, Parag Jain, Anthony Hartshorn
In the race to build smarter AI systems, a counterintuitive pattern has emerged: models that
generate shorter reasoning chains often arrive at correct answers more reliably than those that
think longer. CDS PhD student Yunzhen Feng and his collaborators set out to understand why.
The results contradicted the "longer is better" narrative. When controlling for the question,
it's actually the shorter, the better. The team discovered that abandoned reasoning branches —
paths the model explored but eventually rejected — were the strongest predictor of incorrect answers.
How reinforcement learning after next-token prediction facilitates learning
Why AI Models Think Longer: New Theory Explains Reasoning Breakthrough
NYU Center for Data Science
Authors: Nikolaos Tsilivis, Eran Malach, Karen Ullrich, Julia Kempe
This work provides new theoretical insights into how reinforcement learning after next-token
prediction helps language models develop better reasoning capabilities. The research explains
why this approach facilitates learning and when it provides the most benefit.
From Concepts to Components: Concept-Agnostic Attention Module Discovery in Transformers
Pinpointing Where AI Models Hide Their Concepts: From Safety to Dogs to Mathematical Reasoning
NYU Center for Data Science
Authors: Jingtong Su, Julia Kempe, Karen Ullrich
Understanding where and how concepts are represented in transformer models is crucial for
interpretability and safety. This work introduces a concept-agnostic method for discovering
attention modules in transformers, revealing how models organize information from safety
guidelines to object recognition to mathematical reasoning.
DRoP: Distributionally Robust Data Pruning
Making AI Fairer Through Smarter Data Reduction
NYU Center for Data Science
Authors: A. Vysogorets, K. Ahuja, J. Kempe
Dataset pruning promises to reduce training costs, but traditional approaches can inadvertently
harm model performance on underrepresented groups. DRoP introduces a distributionally robust
approach to data pruning that maintains fairness while achieving efficient data reduction.
Mission Impossible: A Statistical Perspective on Jailbreaking LLMs
AI Language Models' Inevitable Vulnerabilities and New Safeguards
NYU Center for Data Science
Authors: J. Su, J. Kempe, K. Ullrich
From a statistical perspective, jailbreaking LLMs may be fundamentally unavoidable. This work
provides theoretical analysis of why language models remain vulnerable to adversarial attacks
and proposes new approaches to safeguarding AI systems despite these inherent limitations.
The Price of Implicit Bias in Adversarially Robust Generalization
Robustness at a Cost: New Research Reveals Hidden Challenges in AI Security
NYU Center for Data Science
Authors: N. Tsilivis, N. Frank, N. Srebro, J. Kempe
Adversarial training is the gold standard for making AI models robust to attacks, but it comes
with hidden costs. This research examines the implicit bias in adversarially robust generalization
and reveals fundamental tradeoffs in achieving both security and performance.
A Tale of Tails: Model Collapse as a Change of Scaling Laws
Overcoming the AI Data Crisis: A New Solution to Model Collapse
NYU Center for Data Science
Authors: E. Dohmatob, Y. Feng, P. Yang, F. Charton, J. Kempe
As AI models increasingly train on synthetic data, a phenomenon called "model collapse" threatens
their performance. This work provides new theoretical insights into model collapse as a change
of scaling laws and offers solutions for maintaining model quality when training on generated data.
This research was featured in the New York Times.